How shall we build the network from big data,
without losing important information about higher-order dependencies?
Network-based representation has quickly emerged as the norm in representing rich interactions among the components of a complex system for analysis and modeling: movement of hundreds of thousands of ships form a global shipping network, powering the transportation and economy while inadvertently translocating invasive species; interactions of billions of people on social networks, facilitating the diffusion of information.
Given the ship trajectories, to construct a global shipping network, the conventional approach is to count the number of voyages between port pairs as edge weights in the network.
First-order network
While ships from Shanghai to Singapore are in fact more likely to go to Los Angeles according to the raw data, the conventional first-order network captures only pairwise connections in the data and neglects higher-order dependencies, therefore subsequent network analyses that rely on the network structure can potentially lead to incorrect results or conclusions.
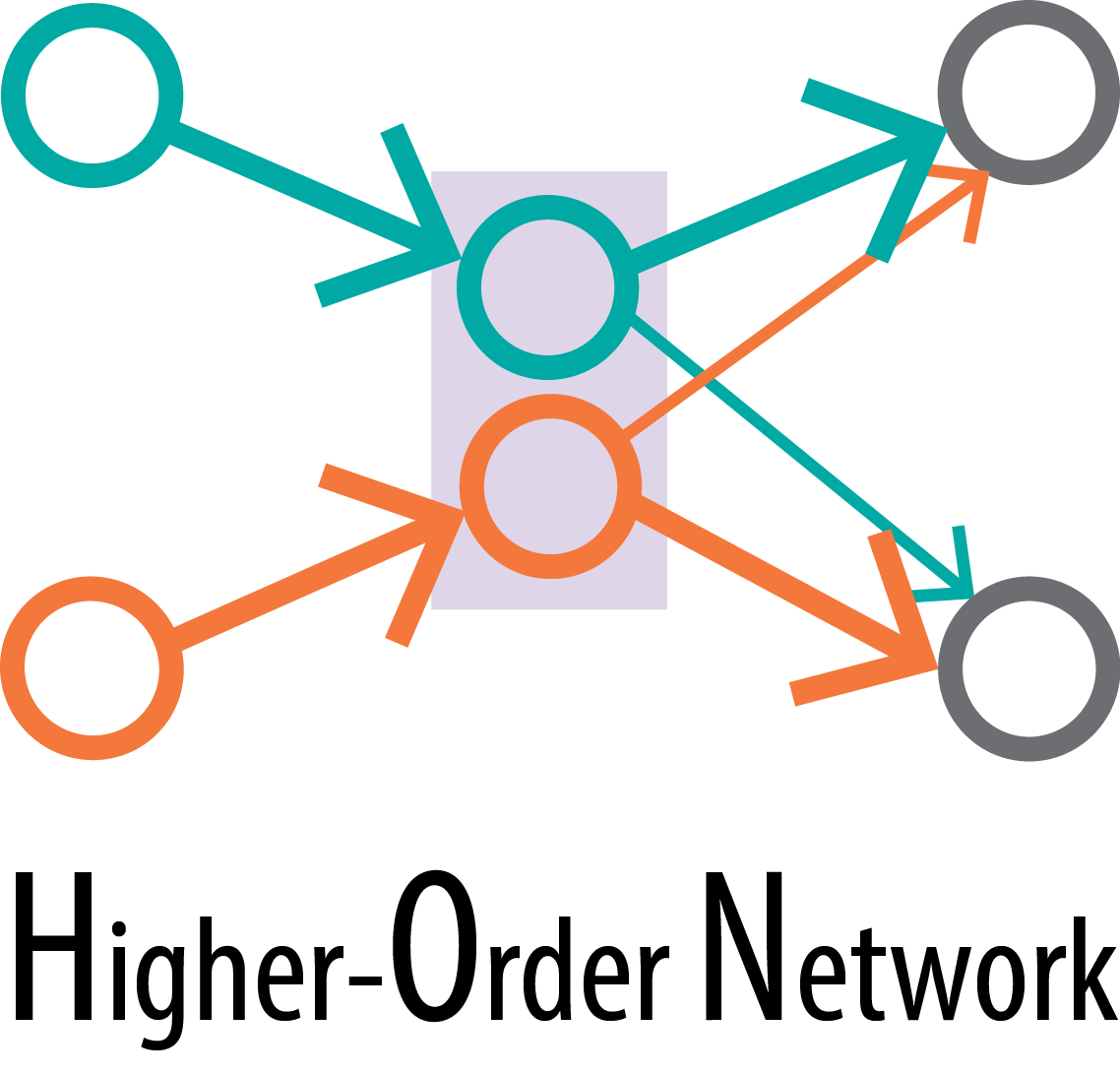
Higher-order network
The higher-order network preserves higher-order dependencies in the network structure, therefore movements simulated on the network more accurately reflects the true movement patterns in the raw data.
Methods in a nutshell

What are the advantages of using HON
instead of the conventional first-order network or the fixed second-order network?
Accuracy
HON is more accurate in representing the true movement patterns in data in comparison with the conventional first-order network or the fixed second-order network, because the higher-order nodes and edges in HON can provide more detailed guidance for simulated movements.
Scalability
HON is more compact than fixed-order networks by using variable orders of dependencies, embedding higher-order dependencies only when necessary. Thus, not only is HON scalable for big data, but also network analysis algorithms run faster on HON.
Compatibility
The data structure of HON is consistent with the conventional network representation, so existing network analysis methods can be applied directly without being modified.
Broad Influence
Existing network analyses either simply ignore higher-order patterns in the data and use the first-order network representation (which is inaccurate), or modify existing algorithms to incorporate higher-order movement patterns (which do not generalize to all algorithms).
The higher-order network resolves this dilemma, by fundamentally improve the network itself, such that network algorithms, without any modification, will be aware of higher-order dependencies.

Application fields beyond shipping

Flow dynamics
Clustering
Ranking
Paper
Jian Xu, Thanuka L. Wickramarathne, and Nitesh V. Chawla. "Representing higher-order dependencies in networks." Science Advances (2016)
Code
Code for generating Higher-order Network (HON) from data with higher-order dependencies.
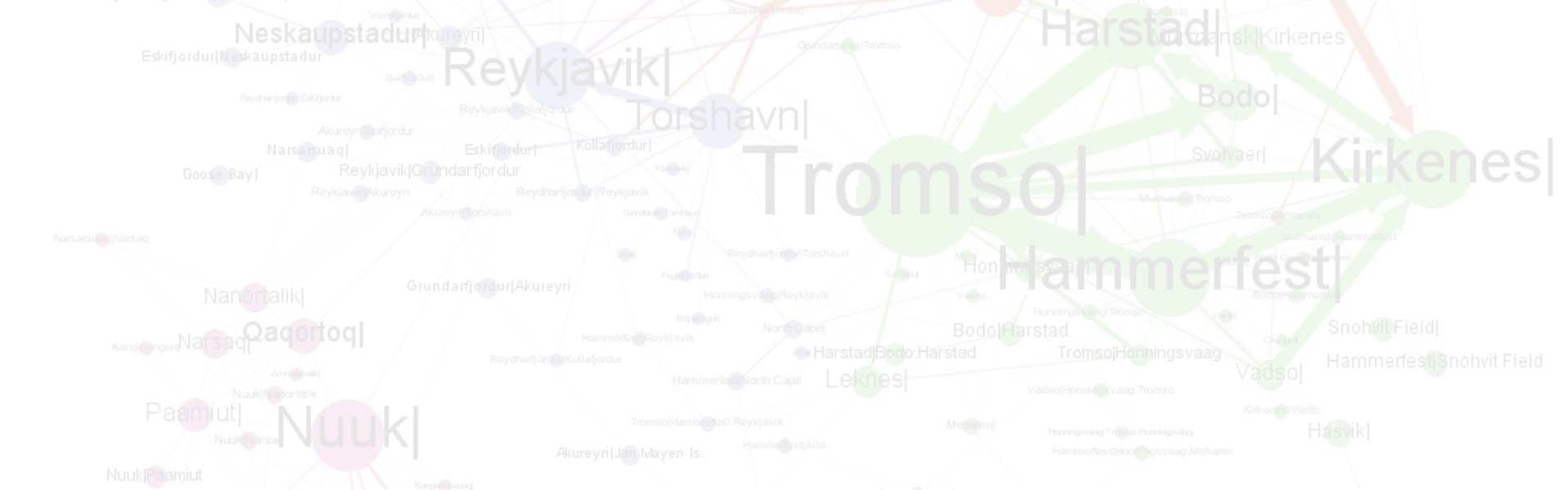
Visualization
HoNVis: a visualization toolkit for interactive exploration of higher-order networks.
HONS @ NetSci 2018
Higher-order Models in Networks
Jun. 12, 2018. Paris, France
Prof. Nitesh Chawla will contribute a talk on the latest developments of HON, including the improved parameter-free algorithm, its application in anomaly detection in sequential data, and modeling species invasion in the Arctic.
Dr. Jian Xu (Lucy Family Institute for Data & Society alumni) will host the morning session “Beyond Markov models”.
Tutorial @ KDD 2018
Beyond Graph Mining: Higher-Order Data Analytics for Temporal Network Data
All-day hands-on tutorial, Aug 19-23, London, UK.
Prof. Nitesh Chawla and/or Dr. Jian Xu (Lucy Family Institute for Data & Society alumni) will give an overview of the higher-order network, and demonstrate HONVis, the visualization and interactive exploration toolkit for HON.